Meilisearch v1.3 is released 🎉
timestamp1691481594187
Let's take a look at some of the most significant changes in Meilisearch's latest update. We’ll go over the main changes in this article, but you can also view the full changelog on GitHub.
v1.3 is now available on Meilisearch Cloud, including all experimental features. Upgrade your Meilisearch instance in one click without downtime.
Experimental feature: vector search
🚀 Using LangChain? You can now use the Meilisearch vector store to benefit from powerful search features!
We are excited to introduce vector storage! Now, you can index and search documents using vector embeddings—numerical representations of data. For the first iteration of this feature, you need to use an external tool such as Hugging Face, Cohere, or OpenAI, to create such embeddings. Check out the announcement post to discover the extensive possibilities and potential applications of this feature.
🧪 This feature is experimental, you can enable it using the new experimental-features endpoint.
To search documents based on their vector proximity, make sure they contain a _vectors field:
curl -X POST -H 'content-type: application/json' \
'localhost:7700/indexes/songs/documents' \
--data-binary '[
{ "id": 0, "_vectors": [0, 0.8, -0.2], "title": "Across The Universe" },
{ "id": 1, "_vectors": [1, -0.2, 0], "title": "All Things Must Pass" },
{ "id": 2, "_vectors": [[0.5, 3, 1], [-0.2, 4, 6]], "title": "And Your Bird Can Sing" }
]'Once stored, you can search your vectorized documents by using the new vector search parameter in combination with the search and multi-search routes.
curl -X POST -H 'content-type: application/json' \
'localhost:7700/indexes/songs/search' \
--data-binary '{ "vector": [0, 1, 2] }'👉 Note that you need to generate the vector in your query using a third-party tool.
The returned documents include a _semanticScore field indicating the semantic similarity—or relevancy—of each document with the query.
{
"hits": [
{ "id": 0, "_vectors": [0, 0.8, -0.2], "title": "Across The Universe", "_semanticScore": 0.6754 },
{ "id": 1, "_vectors": [1, -0.2, 0], "title": "All Things Must Pass", "_semanticScore": 0.7546 },
{ "id": 2, "_vectors": [[0.5, 3, 1], [-0.2, 4, 6]], "title": "And Your Bird Can Sing", "_semanticScore": 0.78 }
],
"query": "",
"vector": [0, 1, 2],
"processingTimeMs": 0,
"limit": 20,
"offset": 0,
"estimatedTotalHits": 2
}📢 This feature is experimental and we need your help to improve it! Share feedback on this GitHub discussion.
New feature: display ranking scores at search
Use the new showRankingScore search parameter to see the ranking score of relevancy of each document:
curl \
-X POST 'http://localhost:7700/indexes/movies/search' \
-H 'Content-Type: application/json' \
--data-binary '{ "q": "Batman Returns", "showRankingScore": true }'Each document in the response will include a _rankingScore property, which represents a score between 0 and 1:
"_rankingScore": 0.8575757575757575The higher the _rankingScore, the more relevant the document is.
Experimental feature: ranking score details
For every document returned, Meilisearch provides a detail of the ranking score of each ranking rule. This feature is a perfect example of how community engagement can enrich the design process at Meilisearch.
🧪 This feature is experimental, you can enable it using the new experimental-features endpoint.
Set the showRankingScoreDetails search parameter to true to view the ranking score details:
curl \
-X POST 'http://localhost:7700/indexes/movies/search' \
-H 'Content-Type: application/json' \
--data-binary '{ "q": "Batman Returns", "showRankingScoreDetails": true }'The response should include the relevancy score of each rule:
"_rankingScoreDetails": {
"words": {
"order": 0,
"matchingWords": 1,
"maxMatchingWords": 1,
"score": 1.0
},
"typo": {
"order": 1,
"typoCount": 0,
"maxTypoCount": 1,
"score": 1.0
},
"proximity": {
"order": 2,
"score": 1.0
},
"attribute": {
"order": 3,
"attributesRankingOrder": 0.8,
"attributesQueryWordOrder": 0.6363636363636364,
"score": 0.7272727272727273
},
"exactness": {
"order": 4,
"matchType": "noExactMatch",
"score": 0.3333333333333333
}
}📢 This feature is experimental. You can help us improve it by sharing your feedback on this GitHub discussion.
New feature: search for facet values
Once you have defined your filterable attributes, you can use the new endpoint POST /indexes/{index}/facet-search to search for facet values.
curl \
-X POST 'http://localhost:7700/indexes/movies/facet-search' \
-H 'Content-Type: application/json' \
--data-binary '{
"facetName": "genres",
"facetQuery": "a"
}'As facet search is typo tolerant and supports prefix search, the above query will return de following results:
{
"facetHits": [
{
"value": "Action",
"count": 5403
},
{
"value": "Adventure",
"count": 3020
},
{
"value": "Animation",
"count": 1969
}
],
"facetQuery": "a",
"processingTimeMs": 0
}To test this feature, check out our updated ecommerce demo.
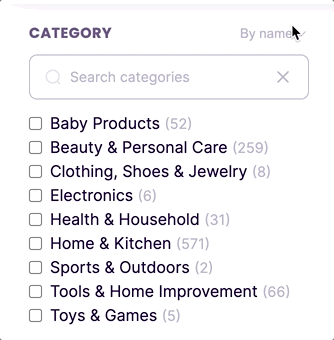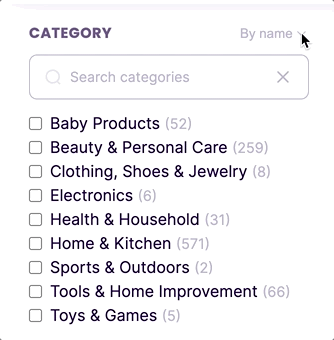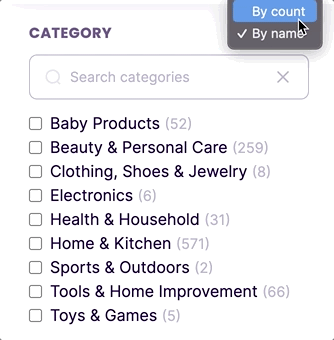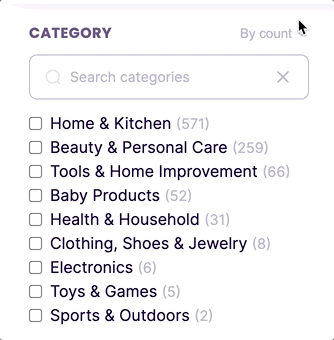
New feature: sort facet values by count
By default, facets are sorted in ascending alphanumeric order. Now, you can sort facet values in descending order based on the number of matched documents containing each facet value.
To order facets by count, you can use the new sortFacetValuesBy property in the faceting index settings.
To modify the order for all facets, you can use the asterisk (*) wildcard:
curl \
-X PATCH 'http://localhost:7700/indexes/movies/settings/faceting \
-H 'Content-Type: application/json' \
--data-binary '{
"sortFacetValuesBy": {"*": "count"}
}'Alternatively, you have the flexibility to order a single facet by count while maintaining alphanumeric ordering for other attributes:
curl \
-X PATCH 'http://localhost:7700/indexes/movies/settings/faceting \
-H 'Content-Type: application/json' \
--data-binary '{
"sortFacetValuesBy": {"*": "alpha", "genre": "count"}
}'You can also try it in the ecommerce demo.
New feature: searchable attributes at query time
With the new attributesToSearchOn search parameter, you can now restrict the search to a subset of the searchable attributes at query time. It accepts an array of strings indicating one or more document attributes:
{
"q": "adventure",
"attributesToSearchOn": ["genre"]
}Given the following documents, the above query will only return document with id 1.
{
"id": 0,
"name": "An Adventure in Space and Time",
"genre": ["drama"]
},
{
"id": 1,
"name": "A Strange and Stubborn Endurance",
"genre": ["adventure"]
}Relevancy change: attribute ranking rule
With v1.3, the attribute ranking rule assigns higher relevancy to documents where the query words appear closer to their position in the query, compared to documents where the query words are farther from their position in the query.
Before, this rule measured relevancy based on the position of the words in the attribute rather than on their position in the search query. Documents with attributes containing the query words at the beginning of the attribute were considered more relevant.
Consider the following query: "Batman the dark knight returns" and the corresponding documents:
{
"id": 0,
"title": "Batman the dark knight returns"
},
{
"id": 1,
"title": "Dark the Batman knight returns"
},
{
"id": 2,
"title": "Batman returns: a retrospective",
"description": "The Dark knight is analyzed in this new Batman documentary"
}Prior to version 1.3, the attribute ranking rule placed document 2 at the top of the list, followed by documents 0 and 1, ranked in a tie.
Since version 1.3, the order is strictly: document 0, document 1, document 2, which provides a more natural ranking.
Other improvements
The
/tasksroute now shows the total number of tasks in the queue using thetotalproperty. It also displays the total number of tasks based on specific filtersEnhanced Japanese support and segmentation
Improvements in the Prometheus
/metricsexperimental feature
Contributors
We are really grateful for all the community members who participated in this release. We would like to thank: @vvv, @jirutka, @gentcys, @cuishuang, @0xflotus, and @roy9495 for their help with Meilisearch.
We also want to send a special shout-out to our Meilistar, @mosuka, for his continuous Japanese improvements on Charabia.
Conclusion
And that’s it for v1.3! Remember to check the changelog for the full release notes, and see you next time!
You can stay in the loop by subscribing to our newsletter. To learn more about Meilisearch's future and help shape it, take a look at our roadmap and come participate in our Product Discussions.
For anything else, join our developers community on Discord.
Did you like this update?
![]()
![]()
![]()
Leave your name and email so that we can reply to you (both fields are optional):